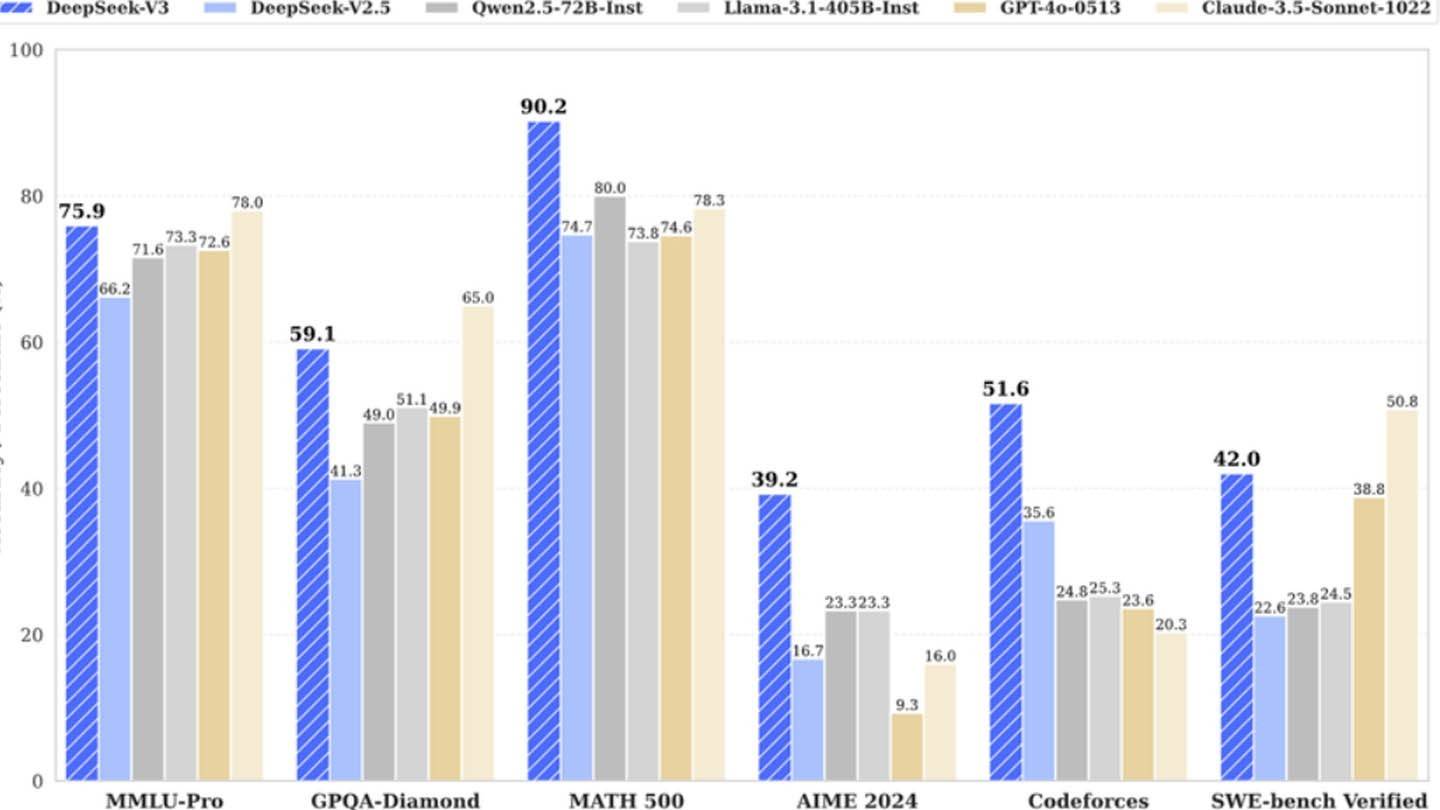
Deepseekの驚くほど安価なAIモデルは、業界の巨人に挑戦しています。中国の新興企業は、競合他社の大幅に高いコストとはまったく対照的である2048 GPUのみを利用して、強力なDeepseek V3ニューラルネットワークをわずか600万ドルで訓練したと主張しています。ただし、この一見低い数値では、研究、洗練、データ処理、インフラストラクチャなどのかなりの費用が省略されています。
Deepseekの革新的なアプローチは、いくつかの重要な技術を活用しています。精度と効率を向上させるためのマルチトークン予測(MTP)。加速トレーニングのために256のニューラルネットワークを採用している専門家(MOE)の混合。重要な文要素への焦点を強化するためのマルチヘッド潜在的注意(MLA)。
 画像:Ensigame.com
画像:Ensigame.com
彼らの公表された数値とは反対に、Semianalysisは、Deepseekが大規模な計算インフラストラクチャを運営しており、複数のデータセンターにわたって約50,000のNVIDIAホッパーGPUを含むことを明らかにしています。これには、10,000 H800、10,000 H100、および追加のH20 GPUが含まれます。
 画像:Ensigame.com
画像:Ensigame.com
中国のヘッジファンドであるHigh-Flyerの子会社であるDeepseekは、クラウドに依存する競合他社とは異なり、データセンターを所有しており、より速いイノベーションと最適化を促進しています。その自己資金によるステータスは、敏ility性と迅速な意思決定に貢献します。さらに、Deepseekはトップの才能を引き付け、一部の研究者は主に中国の大学から年間130万ドル以上を稼いでいます。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekの600万ドルのトレーニングコストは誤解を招くものですが、全体的な投資は5億ドルを超えています。彼らの無駄のない構造は、効率的なイノベーションを促進し、より多くの、より官僚的な企業とは対照的です。実質的な投資、技術の進歩、および熟練チームは、単に「革新的な予算」ではなく、成功の鍵です。コストの格差は明らかです。DeepseekのR1モデルの費用は500万ドル、ChatGPT4Oのトレーニングは1億ドルです。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekのストーリーは、非常に低いコストの物語には慎重な精査が必要ですが、十分に資金提供された独立したAI企業が効果的に競争する可能性を強調しています。