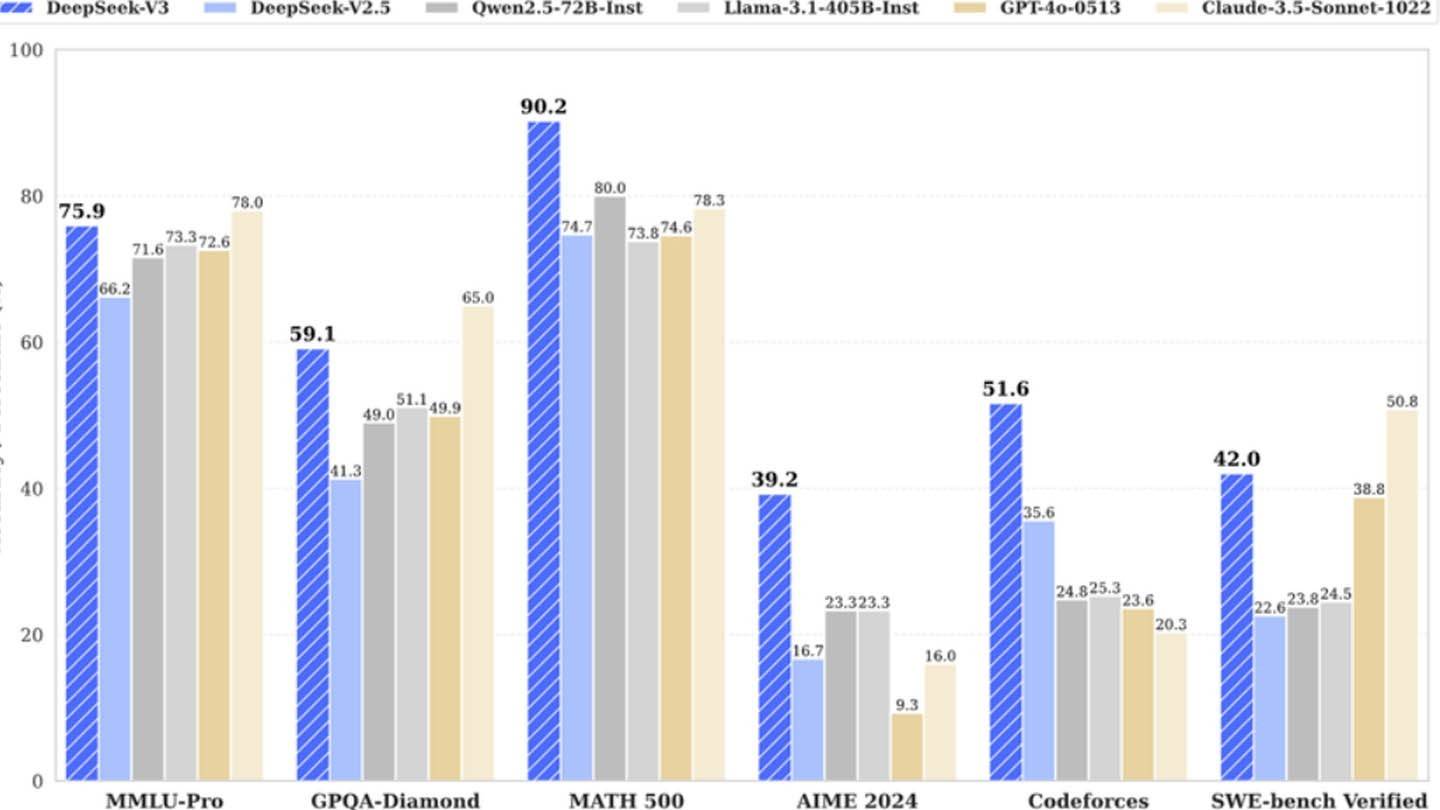
Ang nakakagulat na Deepseek ay murang mga hamon sa modelo ng AI na mga higante sa industriya. Sinasabi ng Startup ng Tsino na sinanay ang malakas na Deepseek V3 Neural Network para sa isang $ 6 milyon lamang, na gumagamit lamang ng 2048 GPUs, isang kaibahan na kaibahan sa mga mas mataas na gastos ng mga kakumpitensya. Ang tila mababang figure na ito, gayunpaman, ay tinanggal ang malaking gastos tulad ng pananaliksik, pagpipino, pagproseso ng data, at imprastraktura.
Ang mga makabagong diskarte ng Deepseek ay gumagamit ng ilang mga pangunahing teknolohiya: Multi-Token Prediction (MTP) para sa pinahusay na kawastuhan at kahusayan; Pinaghalong mga eksperto (MOE) na gumagamit ng 256 neural network para sa pinabilis na pagsasanay; at multi-head latent pansin (MLA) para sa pinahusay na pagtuon sa mga mahahalagang elemento ng pangungusap.
 Imahe: ensigame.com
Imahe: ensigame.com
Taliwas sa kanilang mga na -publish na mga numero, ang semianalysis ay nagpapakita ng Deepseek ay nagpapatakbo ng isang napakalaking computational infrastructure, na sumasaklaw sa humigit -kumulang na 50,000 nvidia hopper GPU sa maraming mga sentro ng data, na kumakatawan sa isang kabuuang pamumuhunan ng server ng humigit -kumulang na $ 1.6 bilyon at mga gastos sa pagpapatakbo malapit sa $ 944 milyon. Kasama dito ang 10,000 H800, 10,000 H100, at karagdagang mga H20 GPU.
 Imahe: ensigame.com
Imahe: ensigame.com
Ang DeepSeek, isang subsidiary ng high-flyer, isang pondo ng hedge ng Tsino, ay nagmamay-ari ng mga sentro ng data nito, hindi katulad ng mga katunggali ng cloud-reliant, na nagpapasigla ng mas mabilis na pagbabago at pag-optimize. Ang katayuan na pinondohan ng sarili ay nag-aambag sa liksi at mabilis na paggawa ng desisyon. Bukod dito, ang Deepseek ay nakakaakit ng nangungunang talento, na may ilang mga mananaliksik na kumikita ng higit sa $ 1.3 milyon taun -taon, lalo na mula sa mga unibersidad sa Tsino.
 Imahe: ensigame.com
Imahe: ensigame.com
Habang ang $ 6 milyong gastos sa pagsasanay ng Deepseek ay nakaliligaw, ang kanilang pangkalahatang pamumuhunan ay lumampas sa $ 500 milyon. Ang kanilang sandalan na istraktura ay nagpapadali ng mahusay na pagbabago, na kaibahan sa mas malaki, mas maraming mga burukratikong kumpanya. Ang malaking pamumuhunan, pagsulong sa teknolohiya, at bihasang koponan ay susi sa kanilang tagumpay, hindi lamang isang "rebolusyonaryong badyet." Ang pagkakaiba -iba ng gastos ay maliwanag: Ang modelo ng R1 ng Deepseek ay nagkakahalaga ng $ 5 milyon, habang ang pagsasanay sa Chatgpt4o ay nagkakahalaga ng $ 100 milyon.
 Imahe: ensigame.com
Imahe: ensigame.com
Ang kwento ng Deepseek ay nagtatampok ng potensyal ng mahusay na pondo, independiyenteng mga kumpanya ng AI upang makipagkumpetensya nang epektibo, kahit na ang salaysay ng pambihirang mababang gastos ay nangangailangan ng maingat na pagsisiyasat.